前言
在学习Hadoop-MapReduce之前,我们首先要搞懂什么是HadoopMapReduce?具体有什么应用场景?
Hadoop-MapReduce作为一种用于处理和生成大规模数据集的分布式计算框架。
从这一点就可以看出来,作为一种处理大规模数据集的分布式框架,肯定有它的优点,特别是在处理和简化大数据方面。 Hadoop-MapReduce 由两个主要部分组成:Map(映射)和 Reduce(归约)
- Map:负责“分”,就是将复杂的任务分解为若干个“简单的任务”来进行并行处理。在map阶段,输入的数据会被分割成独立的块。Hadoop会将这些块分部在不同的节点上进行处理,从而实现数据的并行化处理,从而提高计算效率。
这里独立的块指的是将大规模的输入数据集拆分成多个较小的部分,这个较小的部分称为“块”。 通常在Hadoop中,默认的块大小是128MB或256MB(可以配置) 假设你有一个 1 TB 的大文件需要处理,如果默认块大小为 128 MB,这个文件会被分割成约 8192 个块(1 TB ÷ 128 MB = 8192),然后这些块被分发到集群中的多个节点上进行处理。每个块的处理任务由一个map()函数执行,这样整个文件的处理就变成了多个任务的并行执行,从而大大提高了效率。
- Reduce:负责“合”,就是将map阶段处理好的结果进行全局汇总。
- MapReduce运行在yarn集群(ResourceManager进行资源分配,NodeManager执行具体的运算)
YARN 主要负责协调 Hadoop 集群中的计算资源(如 CPU、内存),允许多个应用程序在同一集群上并发运行。
为了搞懂这些抽象的概念,我就举一个例子带大家了解。
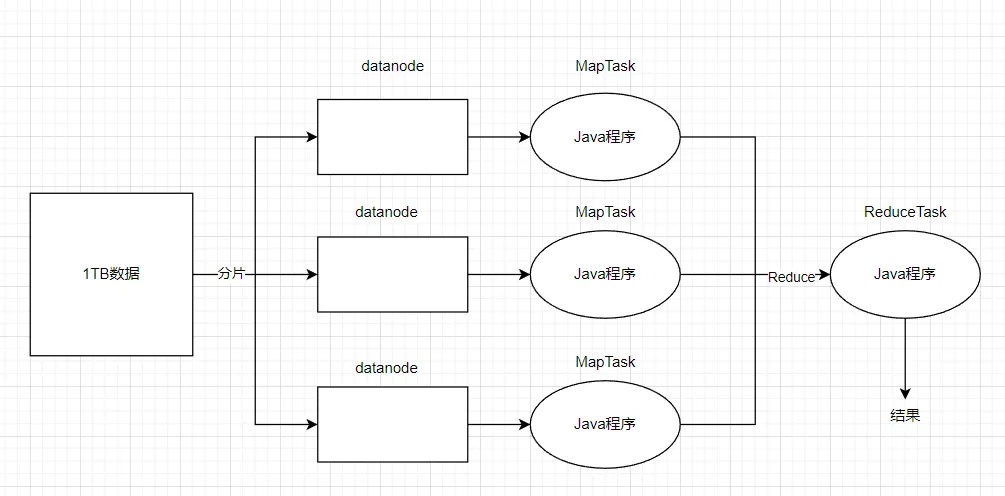
假如说有1TB的数据要处理,那么数据先会经过分片处理后,将数据分配到datanode节点上,然后我们编写好的Java程序就会处理各个节点的任务(MapTask),这个阶段就是Map阶段。在Redcuce阶段,会对Map阶段的输出进行聚合,排序等最终处理,最后生成最终结果。
刚才分析MapReduce的计算过程是在datanode上进行的。那么如果用户想要提交一个任务,它的具体流程是什么样的呢?
MapReduce的计算框架
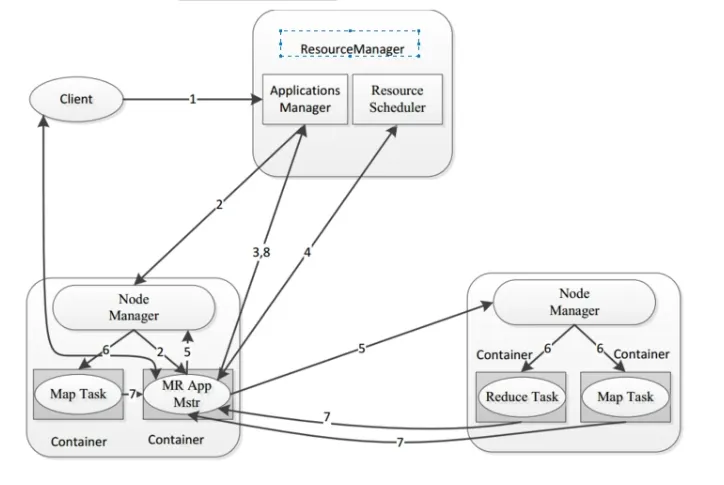
当用户(客户端client)想要提交一个计算任务时,ResourceManager会启动两个模块(Applications Manager和Resource Scheduler)然后Node Manager会启动一个进程App Master,然后App Master会向ResourceManager请求资源(内存,cpu),ResourceManager在收到请求后会由ApplicationManager进行接收,这个时候会由它的中间组件ResourceScheduler进行分配资源,它会告诉AppMaster向哪一个NodeManager获取资源,然后appMaster会将资源列表回复给ResourceScheduler。然后appmaster会向NodeManager分配资源。在资源分配之后,NodeManager会启动MapTask来执行具体的计算任务,同时它还会启动一个ReduceTask,然后ReduceTask会将计算状态和结果汇报给appMaster。最后将结果汇报给applicationMaster。
在了解完MapReduce的基本工作流程之后,那么如何去编写这个业务逻辑处理代码呢?
其实在编写Hadoop MapRedcuce的业务处理代码时,主要分为两个部分:Map函数和Redcuce函数。这些函数的实现通常使用Java语言来实现。 在后续的讲解中,我会详细的讲解编写思路以及过程。
MapReduce的编程规范
在进行MapRedcuce开发时一共八个步骤,其中Map阶段两个步骤,Shuffle阶段4个步骤,Reduce阶段2个步骤。
Map阶段的两个步骤:
- 设置InputFormat类,将数据切分为Key-Value(k1和v1),输入到第二步
- 自定义Map逻辑(编写Map函数),将第一步的结果转换成另外的Key-Value(K2和V2)对,输出结果。
Shuffle阶段4个步骤:
- 对输出的Key-Value对进行分区
- 对不同分区的数据按照相同的Key排序
- (可选)对分组过的数据初步规约,降低数据的网络拷贝
- 对数据进行分组,相同Key的Value放入到一个集合中
Reduce阶段2个步骤:
- 对多个Map任务的结果进行排序以及处理,编写Redcuce函数实现自己的逻辑,对输入的Key-Value进行处理,转为新的Key-Value(K3和V3)输出
- 设置OutputFormat处理并保存Redcuce输出的Key-Value数据
下面我们看一个案例
WordCount词频统计
需求:在Linux系统本地创建两个文件,即文件wordfile1.txt和wordfile2.txt。针对这两个小数据集样本编写的MapReduce词频统计程序,不作任何修改,就可以用来处理大规模数据集的词频统计。
过程分析:
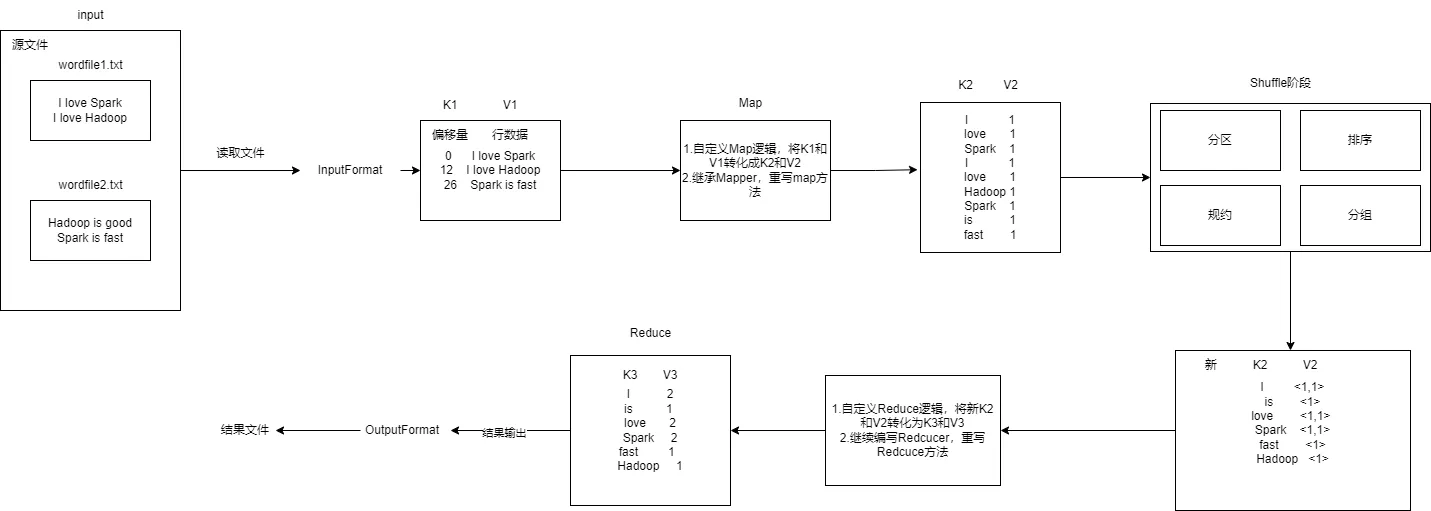
- 重写map方法
/*
Mapper<Object, Text, Text, IntWritable>:四个参数分别表示K1,V1,K2,V2
重写map方法的目的就是将<k1,v1>转化为<k2,v2>,k1是每一行数据的行偏移量,v1是行数据。k2是单词,v2出现次数
数据类型:v1行偏移量是int类型,这里不能用基本数据类型,要用封装类型Object。Text类型是k1的封装类型存储行数据。IntWritable是int的封装类型存储次数
*/
public static class TokenizerMapper extends Mapper<Object, Text, Text, IntWritable> {
private static final IntWritable one = new IntWritable(1); //由于V2的值都为1,实现序列化
private Text word = new Text(); //下面要用到K2,这里先创建一个Text类型的K2对象word
public TokenizerMapper() {
}
/*
map(Object key, Text value, Context context):前两个参数表示的是k1和v1,最后一个参数context表示的是上下文对象
*/
public void map(Object key, Text value, Mapper<Object, Text, Text, IntWritable>.Context context) throws IOException, InterruptedException {
StringTokenizer itr = new StringTokenizer(value.toString()); //将传入的字符串 value 按默认的空格分隔符拆分成若干个子字符串(token)
while(itr.hasMoreTokens()) {
this.word.set(itr.nextToken());//将token写入k2
context.write(this.word, one);//传给下一个上下文对象比如reduce
}
}
}
- 重写redcuce方法
/*
Reducer<Text, IntWritable, Text, IntWritable>:四个参数分别表示新的k2,v2和k3,v3
*/
public static class IntSumReducer extends Reducer<Text, IntWritable, Text, IntWritable> {
private IntWritable result = new IntWritable();//存储结果次数v3
public IntSumReducer() {
}
/*
reduce(Text key, Iterable<IntWritable> values, Context context):第一个参数是新k2,第二个参数是新v2表示一个集合例如<1,1>,context是上下文对象
*/
public void reduce(Text key, Iterable<IntWritable> values, Reducer<Text, IntWritable, Text, IntWritable>.Context context) throws IOException, InterruptedException {
int sum = 0;
IntWritable val;
for(Iterator i$ = values.iterator(); i$.hasNext(); sum += val.get()) {
val = (IntWritable)i$.next();//将values集合求和
}
this.result.set(sum);
context.write(key, this.result);
}
}
}
- 编写main方法
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();//创建一个配置类,后面使用job对象时要用到
String[] otherArgs = (new GenericOptionsParser(conf, args)).getRemainingArgs();//获取除hadoop参数以外的其他参数
if(otherArgs.length < 2) { //如果参数数量小于2个异常退出,输出异常信息
System.err.println("Usage: wordcount <in> [<in>...] <out>");
System.exit(2);
}
Job job = Job.getInstance(conf, "word count");//创建一个 Job 对象,表示 MapReduce 作业,主类名为word count
job.setJarByClass(WordCount.class);//设置运行jar程序启动的主类为WordCount.class
job.setMapperClass(WordCount.TokenizerMapper.class);//设置Mapper的主类
job.setCombinerClass(WordCount.IntSumReducer.class);//设置combiner主类(可选)
job.setReducerClass(WordCount.IntSumReducer.class);//设置Reducer主类
job.setOutputKeyClass(Text.class);//设置输出键k3的数据类型
job.setOutputValueClass(IntWritable.class); //设置输出值V3的数据类型
for(int i = 0; i < otherArgs.length - 1; ++i) {//将所有数据以文件输入的格式添加到job的输入路径中
FileInputFormat.addInputPath(job, new Path(otherArgs[i]));
}
FileOutputFormat.setOutputPath(job, new Path(otherArgs[otherArgs.length - 1]));//设置输出格式为文件输出格式,并将作业输出到最后一个参数的路径目录下
System.exit(job.waitForCompletion(true)?0:1);//等待正常退出
}
实验步骤
- 创建两个文件分别为wordfile1.txt和wordfile2.txt文件
cd ~
gedit wordfile1.txt
写入下列内容,保存并退出
I love Spark
I love Hadoop
同样的方法创建一个worldfile2.txt文件
gedit wordfile2.txt
写入下列内容
Hadoop is good
Spark is fast
- 启动hdfs并上传文件到
hdfs://localhost:9000/user/hadoop/input下
start-dfs.sh
hdfs dfs -mkdir input #创建文件目录
将刚才创建的wordfile1.txt和wordfile2.txt上传到input下
hdfs dfs -put ~/wordfile1.txt input
hdfs dfs -put ~/wordfile2.txt input
- 编写完整词频统计程序
cd /usr/local/eclipse
./eclipse
新建一个项目
添加以下jar包:
/usr/local/hadoop/share/hadoop/common目录下的hadoop-common-3.1.3.jar和haoop-nfs-3.1.3.jar;/usr/local/hadoop/share/hadoop/common/lib目录下的所有JAR包;/usr/local/hadoop/share/hadoop/mapreduce目录下的所有JAR包,但是,不包括jdiff、lib、lib-examples和sources目录,具体如下图所示。/usr/local/hadoop/share/hadoop/mapreduce/lib目录下的所有JAR包。
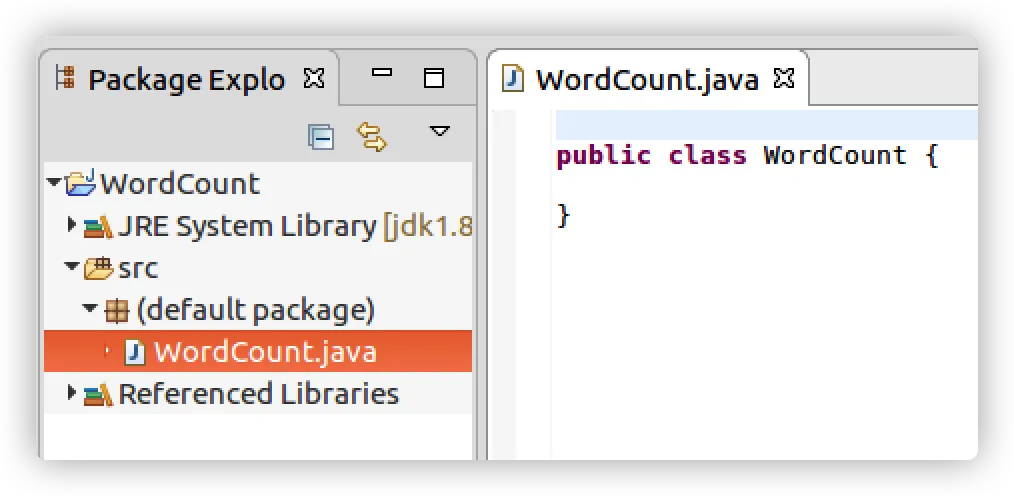
写入下列代码
import java.io.IOException;
import java.util.Iterator;
import java.util.StringTokenizer;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.util.GenericOptionsParser;
public class WordCount {
public WordCount() {
}
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
String[] otherArgs = (new GenericOptionsParser(conf, args)).getRemainingArgs();
if(otherArgs.length < 2) {
System.err.println("Usage: wordcount <in> [<in>...] <out>");
System.exit(2);
}
Job job = Job.getInstance(conf, "word count");
job.setJarByClass(WordCount.class);
job.setMapperClass(WordCount.TokenizerMapper.class);
job.setCombinerClass(WordCount.IntSumReducer.class);
job.setReducerClass(WordCount.IntSumReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
for(int i = 0; i < otherArgs.length - 1; ++i) {
FileInputFormat.addInputPath(job, new Path(otherArgs[i]));
}
FileOutputFormat.setOutputPath(job, new Path(otherArgs[otherArgs.length - 1]));
System.exit(job.waitForCompletion(true)?0:1);
}
public static class TokenizerMapper extends Mapper<Object, Text, Text, IntWritable> {
private static final IntWritable one = new IntWritable(1);
private Text word = new Text();
public TokenizerMapper() {
}
public void map(Object key, Text value, Mapper<Object, Text, Text, IntWritable>.Context context) throws IOException, InterruptedException {
StringTokenizer itr = new StringTokenizer(value.toString());
while(itr.hasMoreTokens()) {
this.word.set(itr.nextToken());
context.write(this.word, one);
}
}
}
public static class IntSumReducer extends Reducer<Text, IntWritable, Text, IntWritable> {
private IntWritable result = new IntWritable();
public IntSumReducer() {
}
public void reduce(Text key, Iterable<IntWritable> values, Reducer<Text, IntWritable, Text, IntWritable>.Context context) throws IOException, InterruptedException {
int sum = 0;
IntWritable val;
for(Iterator i$ = values.iterator(); i$.hasNext(); sum += val.get()) {
val = (IntWritable)i$.next();
}
this.result.set(sum);
context.write(key, this.result);
}
}
}
- 导出java程序打包生成jar包
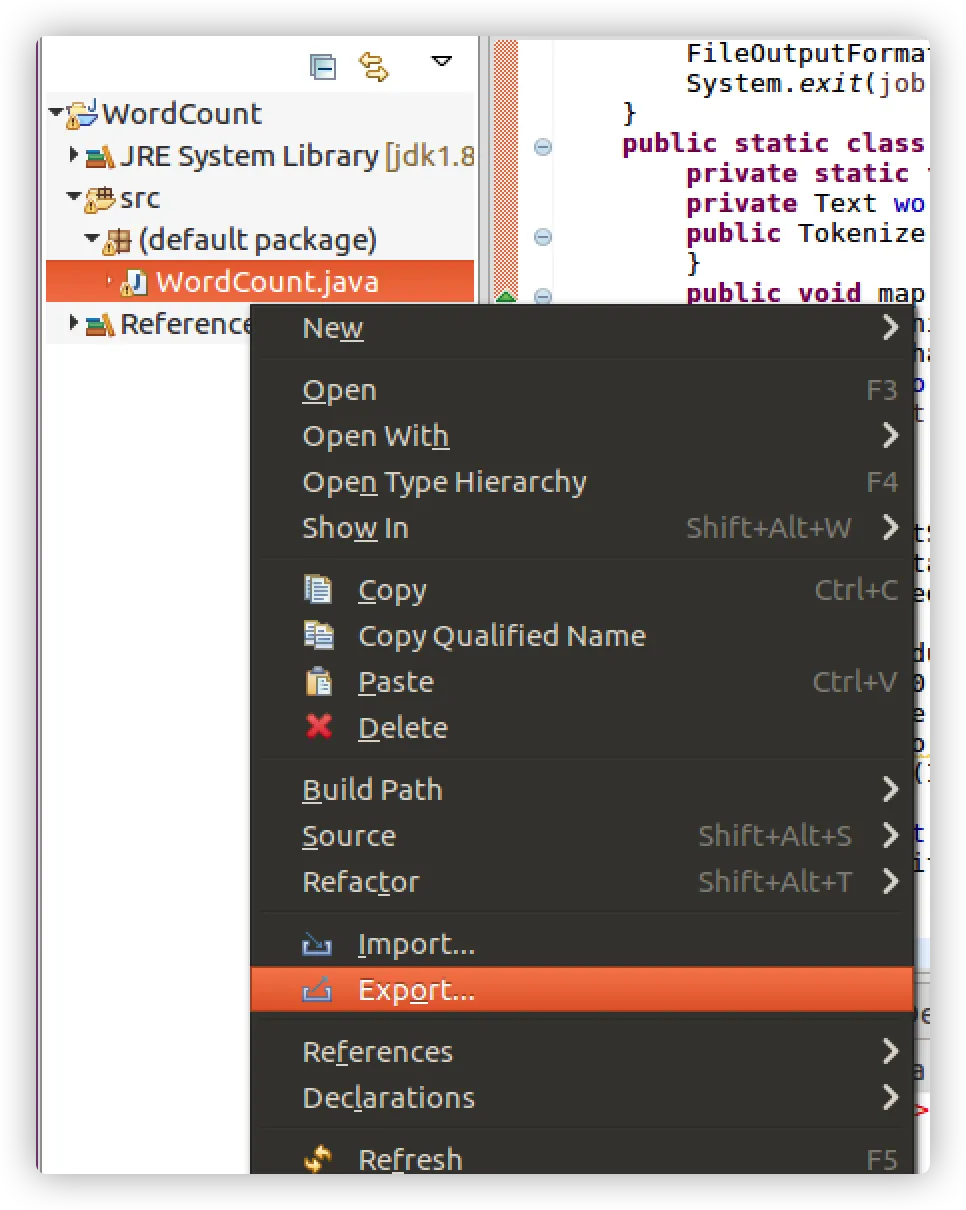
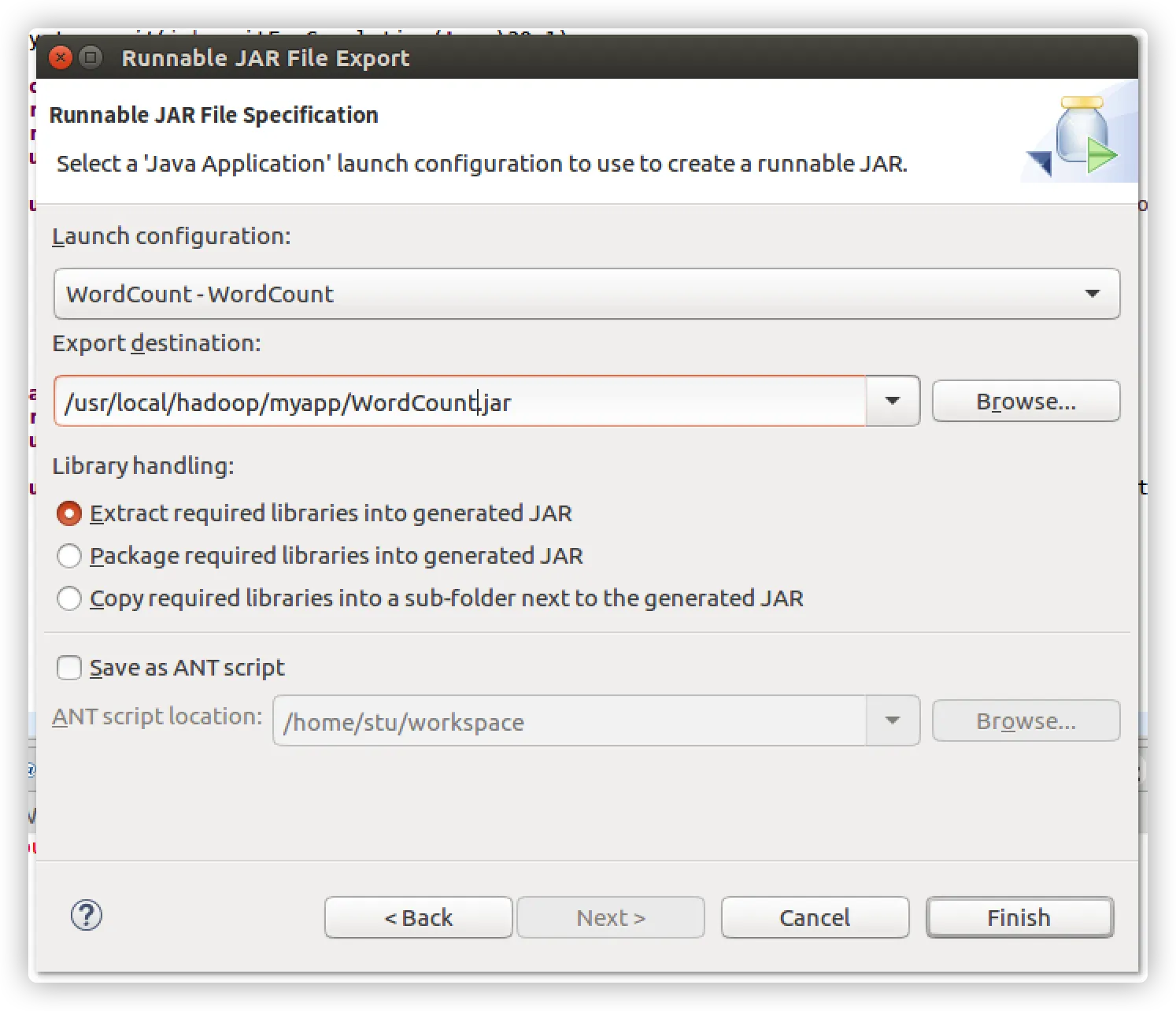
- 进入Myapp下
cd /usr/local/hadoop/Myapp
ls
- 运行jar程序
hadoop jar WordCount.jar input output
查看结果
hdfs dfs -cat output/*
结果如下:
Hadoop 2
I 2
Spark 2
fast 1
good 1
is 2
love 2
注意:下次运行要删除output目录否则会报错,或者加上
// 判断输出文件是否存在 若存在 则删除
Path path = new Path("填入路径");
FileSystem fileSystem = path.getFileSystem(conf);
if (fileSystem.exists(path)) {
fileSystem.delete((path),true);//true表示递归删除
}